在本地部署AI服务(AI chat)
可断网离线使用。用于学习,协助学习提问聊天。电脑要求,最好有nvidia显卡,并且需要安装nvidia的cuda驱动和扩展库来支持AI计算。没有显卡只有GPU也没问题,只是响应速度会慢。
安装运行服务需要一定的开发环境,比如docker 快速安装open-webui

结合后端ollama服务,前端open-webui页面,模拟ChatGPT。
下载启动ollama
ollama是开源的LLM应用程序,用于加载和识别LLM模型,基于llama.cpp
下载后启动即可
获取训练模型
已知的模型有Meta公司的开源llama2 llama3 google的gemma 我们下载这些模型后 通过ollama运行这些模型
# 下载模型
ollama pull gemma
# 我们也可以直接运行 下载完成后 ollama 自己会直接运行
ollama run gemma
部署前端
部署前端页面,通过页面聊天访问这些模型,并将模型返回的结果显示在页面,实现AI聊天互动.
我们可以使用 open-webui 、 ollama-ui 等开源的前端项目或者自己编写前端代码对接ollama api。
使用docker 安装
这里快速点可以直接使用docker部署 open-webui 文档
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
# 如果没有显卡,则去除 --gpus all 参数
使用pip安装(python)
pip install open-webui
open-webui serve #启动
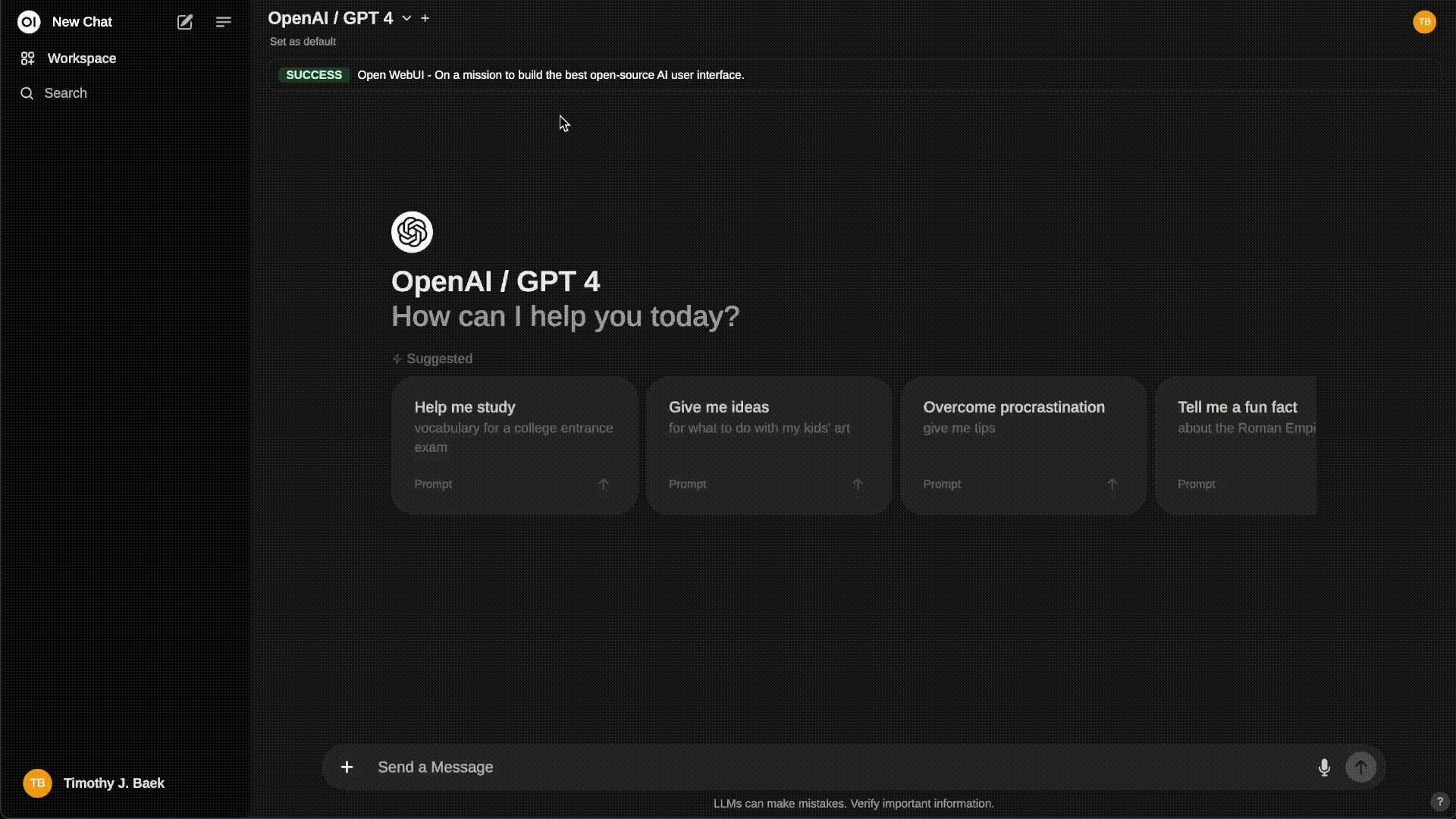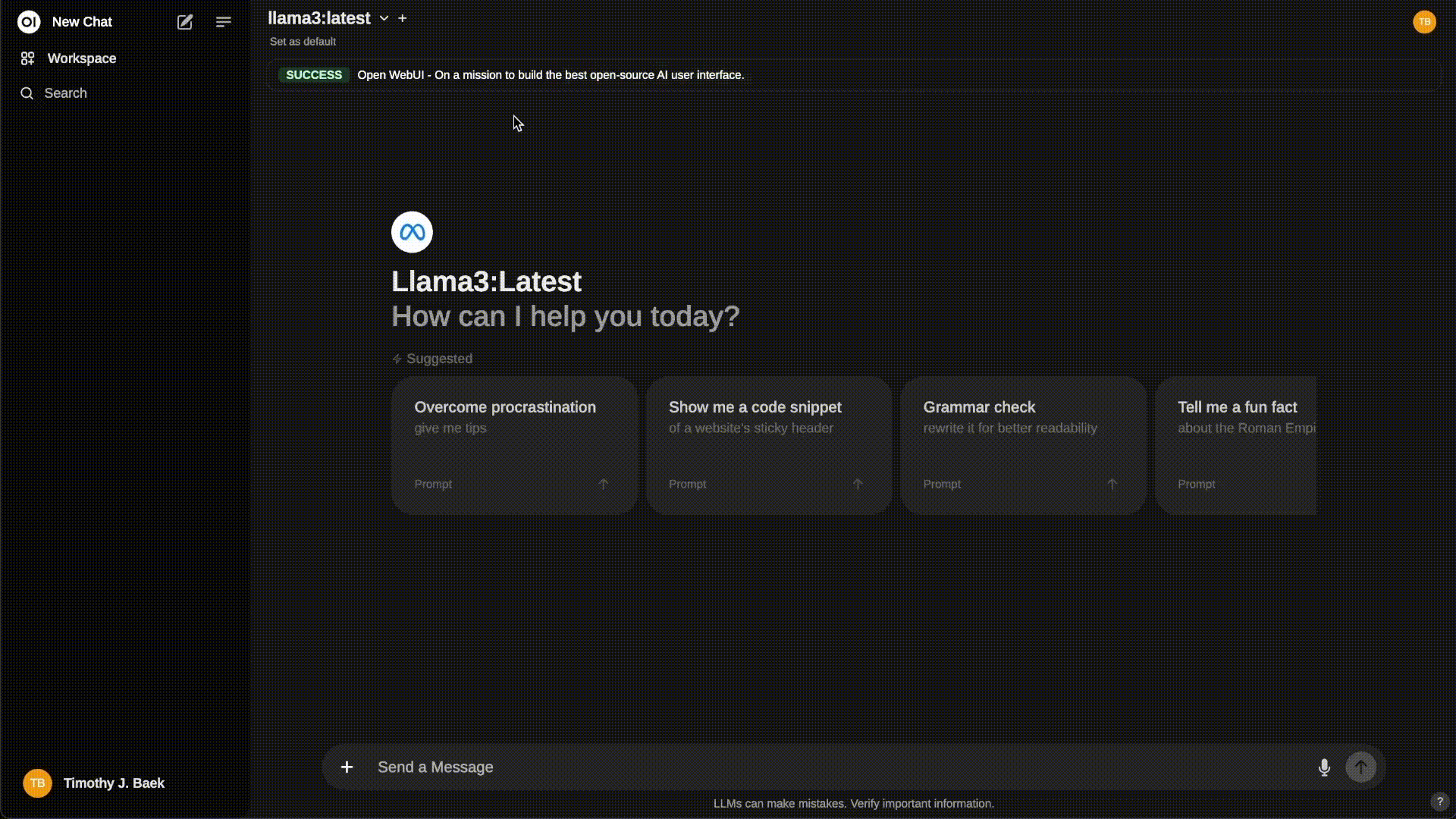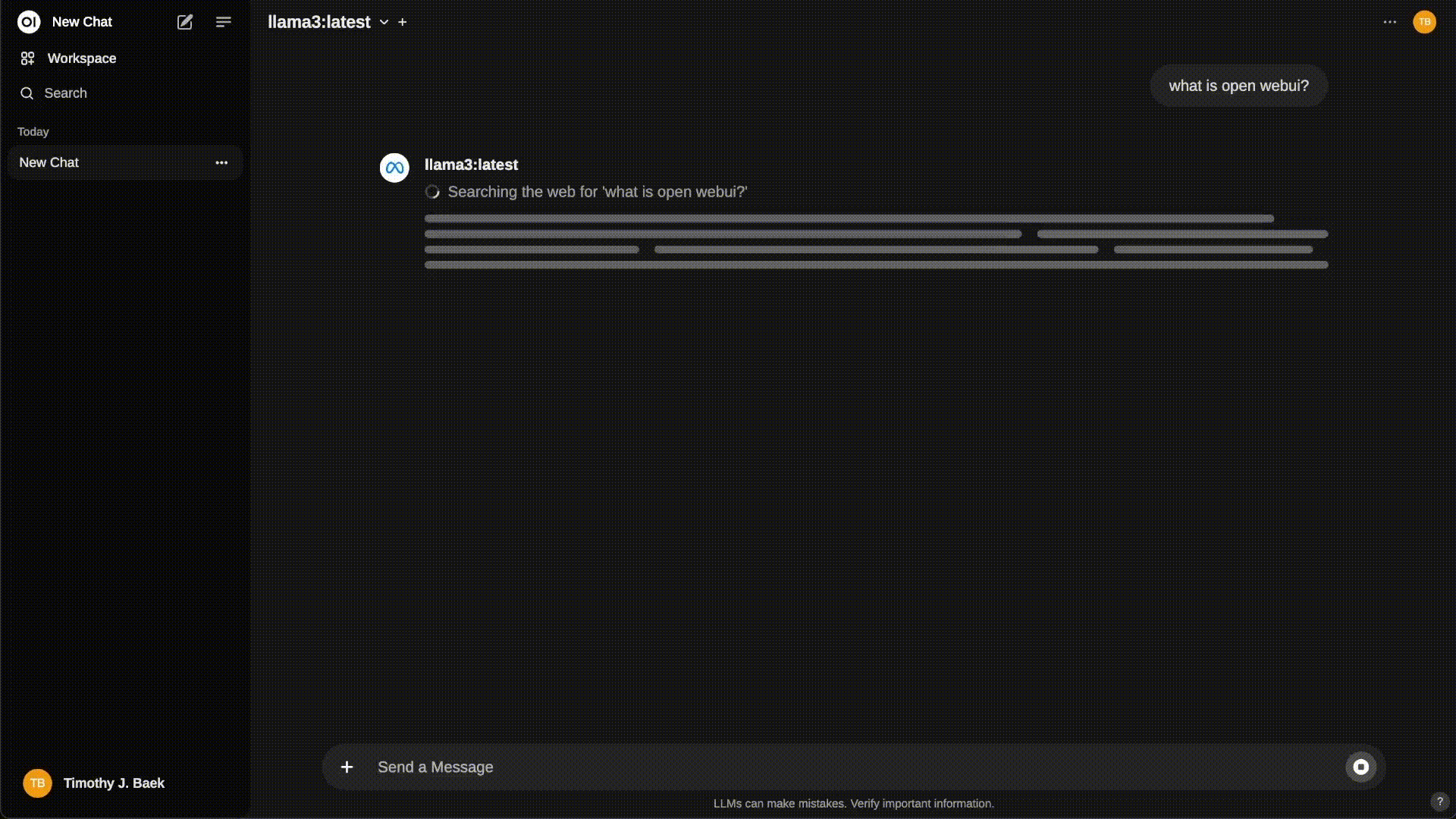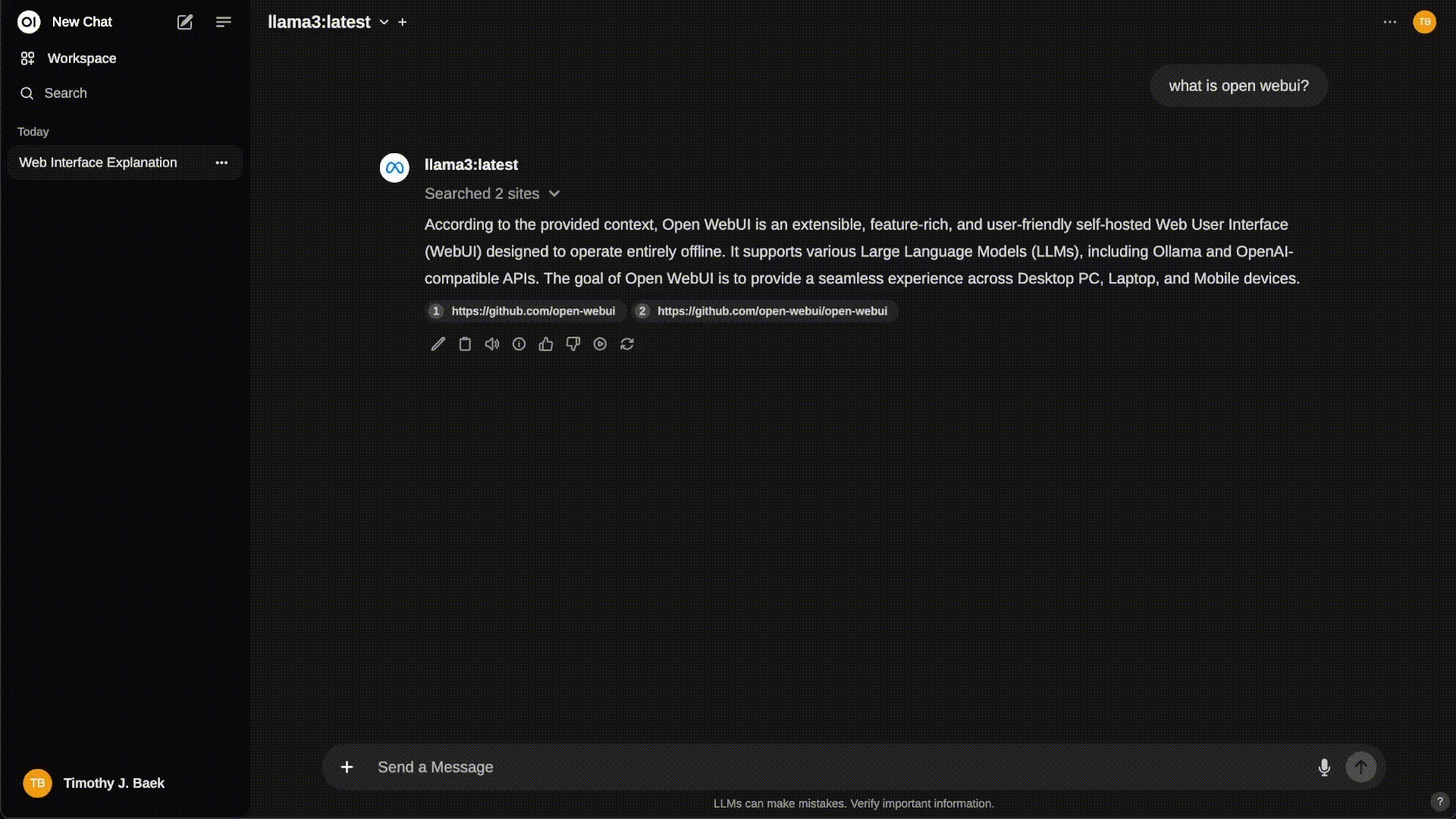
启动后访问即可提问

调试配置
配置参数 实现模型回答内容微调以及页面聊天的个性化设置,包括提问回答内容质量设置等。
可以在ollama下载模型,open-webui会直接显示模型列表。



